
Introduction
 At Excelero, we’re obsessed with making high performance, scalable distributed storage where all the NVMe bandwidth is available to applications at ultra low and consistent latency. We’ve been learning a lot from actual customer deployments like InstaDeep and we know that while one can partition resources in the controlled environment of a PoC or trade-show demo, it’s difficult to do so in a production environment. This is why we built NVMesh to provide maximum flexibility in how applications consume available storage resources – from both a media and networking perspective.
At Excelero, we’re obsessed with making high performance, scalable distributed storage where all the NVMe bandwidth is available to applications at ultra low and consistent latency. We’ve been learning a lot from actual customer deployments like InstaDeep and we know that while one can partition resources in the controlled environment of a PoC or trade-show demo, it’s difficult to do so in a production environment. This is why we built NVMesh to provide maximum flexibility in how applications consume available storage resources – from both a media and networking perspective.
For the last couple of years we’ve been following the developments in AI/ML, especially around remote asynchronous direct memory access from GPUs bypassing CPUs. This is not a new development; it started almost 10 years ago with GPUDirect. Given the incredible pace of GPU processing power growth it is clear that RAM size increases can’t satisfy this growth. You can’t “feed the beast” from RAM alone, you have to stage the data from somewhere else, namely flash, and specifically NVMe flash. When the right use case arises this direct access method will need to be extended to storage access.
The quickly expanding application of Machine Learning in the areas of medical imaging, geospatial imaging and autonomous cars combined with the movement of elements of the workflow to GPU with RAPIDS provide exactly such a case: Huge amounts of raw data stressing all parts of the model training pipeline – from raw data ingest, through Extract-Transform-Load and to model iteration.
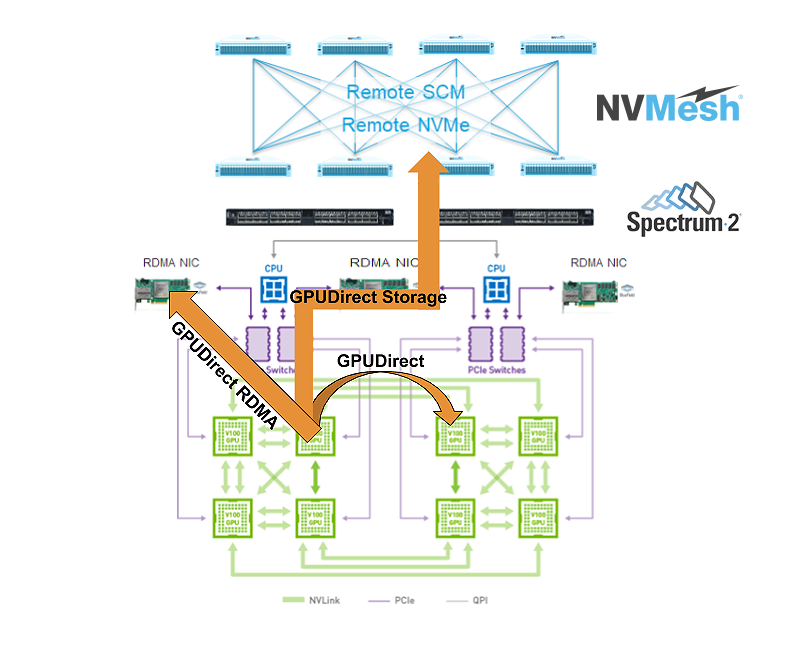
Current work
We were happy to see the first step in this direction, a research project presented by Nvidia, Mellanox and several other parties at GTC 2019.
While local NVMe storage access is important, having 30TB of storage for 16 GPUs that collectively churn over 14TB per second (from memory), and at over 250GB/s via their PCIe connectivity means that it can only partially solve the problem. The 8 NVMe drives can supply only 25GB/s. With about 100GB/s of network bandwidth available, we think that remotely accessed, massively scale-out storage will play a significant part in providing the storage solution for demanding workloads in GPU clusters. I’ll focus on this part in this blog post.
The presenters (mentioned above) chose to implement such a remote access using standard NVMe-over-Fabrics (NVMe-oF) protocol, allowing the initiator part of this protocol to run on GPU and utilizing Peer Direct technology from Mellanox, to pass data directly between HCA and the GPU memory – bypassing CPU on the initiator. When using Mellanox’s HCA on the target side with NVMe-oF Target Offload one can achieve full CPU bypass on both sides.
Is it enough?
This method is a great first step but to really leap forward we need more than that. I will focus on three points concerning applicability of such technology considering real world constraints.
Bandwidth partitioning
Consider a DGX-2 or similar box with 8 RoCE/IB NICs each providing 100Gbps throughput. How do you partition this aggregated bandwidth between the GPUs? What do you do when the next generation supports even higher throughput or has more GPUs in a box?
Ideally, one shouldn’t need to care about this and just allow the GPUs to dynamically use whatever bandwidth they need at any moment, even bursting up to the maximal bandwidth. When using NVMe-oF, link aggregation is only available when there are ports exposing a shared namespace. One might have an NVMe-oF JBOF providing such a shared namespace but rarely can such a JBOF match the overall throughput of a DGX-2 and the requirement form a 1:1 relationship between each DGX and JBOF is unrealistic. In the case of a scale-out NVMe-oF appliance the internal appliance traffic adds network hops and, therefore, latency, since there is no way to know from the GPU itself where the data resides in the network.
Only a flexible solution with client-based data services and an ability to have a namespace stretched over any number of NVMe devices alleviates the need for bandwidth partitioning while maintaining consistently low latency. This is exactly what NVMesh does: It allows creation volumes stretched over unlimited numbers of NVMe drives and network ports providing any bandwidth required from any of the GPUs regardless of burst bandwidth.
Congestion prevention
Bringing massive amounts of data quickly to a number of GPUs may cause a situation where the link from a source of data is overloaded and congested. NVMe-oF read requests are small so the controller that should serve them can get quite a lot of them. In spite of this, there is no built-in mechanism to cope with the congestion on the egress port created by these requests so one gets either significant read latency jitter, underutilized bandwidth or both.
Excelero’s IP allows NVMesh to handle read rate limitation without underutilization of link bandwidth while keeping latency jitter to a minimum.
Memory semantics protocol
NVMesh uses RDDA protocol which is fully based on RDMA transactions following memory semantics. Memory semantics are native to GPUs supporting GPUDirect RDMA and GPUDirect RDMA Async. NVMe-oF, on the other hand, required supporting messaging semantics (Send and Receive for request and response capsule communication) in addition to the memory semantics inherently leading to more branching, and therefore lower GPU utilization.
Conclusion
We see direct access from GPUs to massively scale-out remote NVMe and in the future, persistent memory based storage, as a necessary next step to solve infrastructure bottlenecks arising from the application of distributed Machine Learning to hard, real-life problems. We invite the interested parties – customers, infrastructure vendors or CSPs to share their views, insights and research and to contact us to promote this important direction.




